Mozilla最近制作了一个开源的粤语识别引擎
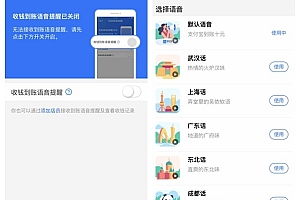
尽管已经有许多智能语音助手技术,但是它们也需要相关的语音识别系统的支持。 对于广东话,此类资源当前仅大型企业可以做到。 有鉴于此,Mozilla最近制作了一个开源的广东话识别引擎,希望允许中小企业和独立开发者使用该技术。

Mozilla的Common Voice 本身涵盖了世界各地的多种语言。 希望通过开源可以降低语音识别引擎开发的门槛。 通过众包收集大量语音数据,以使辨识引擎得以普及。 解决目前数据被大公司垄断情况。 在此计划中,还包括广东话。 Mozilla说:为了打破“大平台”的垄断,并允许语音数据公开和自由地使用,Mozilla还将创建一个名为Deep Speech的开源语音识别引擎,众多人的参与将使语音识别技术变得更好。
说到广东话,对香港人来说当然是最擅长的。 因此,Mozilla邀请香港人提供语音样本,只要他们在其网站上注册或联系电子邮件团队即可参与。 参与者需要在公共领域提供粤语句子,审查句子的正确性; 给句子录音; 并验证检验是否与句子一致。 计划收集的数据越丰富,就可以制作出越准确的语音,从而为粤语语音识别应用程序带来更好的效果。